Direct IO for predictable performance
About direct IO, I almost learned all from the project of foyer.
Direct IO is widely used by the database or storage systems, which will bypass the page cache to manage memory by self for better performance.
Nevertheless, for the majority of other systems that are not bound by CPU or I/O constraints, buffer IO is good enough.
So direct IO is not suitable for the most systems, but today I want to introduce this for the bigdata shuffle system. Let me tell you why and how to do this!
Motivation
The issue of https://github.com/zuston/R1/pull/19 has described the problem of buffer IO for the Apache Uniffle.
Without direct IO, the performance is unstable when the page cache is flushing back to the disk under the tight system memory, which will make the RPC of getting data from memory/local disk latency high.
Actually, for the shuffle based storage, the flush disk blocks size is large like 128M, and for Uniffle, it also will use the large memory to cache data to speed up. From this point, there is no need to use the system page cache.
Requirements
- Having enough memory to maintain alignment memory blocks pool for your system
- Having the Rust knowledge
- Having big enough data(MB+) into the disk
Just do it
Rust standard library of direct flag
The article will only be scoped on the Linux system. And we can activate direct IO directly from the standard library. The code follows as
Write
let path = "/tmp/";
let mut opts = OpenOptions::new();
opts.create(true).write(true);
#[cfg(target_os = "linux")]
{
use std::os::unix::fs::OpenOptionsExt;
opts.custom_flagsO_DIRECT;
}
let file = opts.open(path)?;
file.write_at(data, offset)?;
file.sync_all()?;
Read
let mut file = File::open(path)?;
#[cfg(target_family = "unix")]
use std::os::unix::fs::FileExt;
// read_size indicated the size of read
// read_buf is to fill the read data
// read_offset indicates the reading start position
let read_size = file.read_at(&mut read_buf[..], read_offset)?;
That's all, so easy, right?
Alignment of 4K to write and read
The key point is not described in the above code examples. All read/write buffer must be aligned with the 4K, that means the 16K buffer size is legal, but 15K is illegal. Because for the layer of disk hardware, it only accept alignment buffer.
So if you want to write the 1K data into disk, you should do the following steps
- Creating the 4K buffer which should be placed in continuous memory region
- Filling the 1K data into the 4K buffer from the 0 position
- Using the above code example to write the 4K buffer into the disk
Ways to handle different sizes write and read
For different operations to handle 4K alignment as follows
Read with 5K (>4K)
- Creating the 8K buffer
- Reading
- Remove the tail 3K data for invoking side
Read with 3K
- Creating the 4K buffer
- Reading
- Remove the tail 1K data
Write with 5K
- Creating the 8K buffer
- Write the data into disk
Attention: when reading, you must to filter out the extra data that is the cost.
Append with 5K in multi times
For the first round that the file haven't any data
- Creating the 8K buffer
- Write the data into disk

For the second round with 5K that the file has data
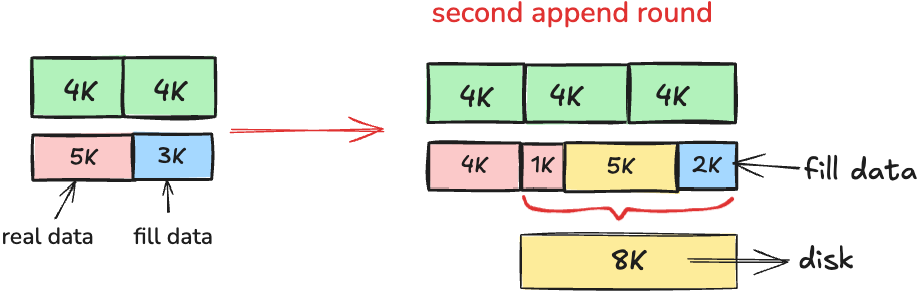
- Reading the tail of 1K (5K - 4K) data from disk (that is written by the last round writing)
- Use the step1's 1K + 5K = 6K to align with 4K, so you have to use the 4K * 2 = 8K buffer, creating it
- Append the data
Alignment memory buffer pool
Above the examples, we know we have to request the continuous memory region. If the machine don't have the enough memory, the page fault will occur.
for the direct io, we have to self manage the align buffer and disk block, if you don't use aligned buffer pool, the page fault will occur frequently, that will also make system load high. (this has be shown in the above screenshot)
For the project of riffle, I created total 4 * 1024 / 16 number buffers and one buffer has 16M.
Let's see the metrics of machine with and without buffer pool.
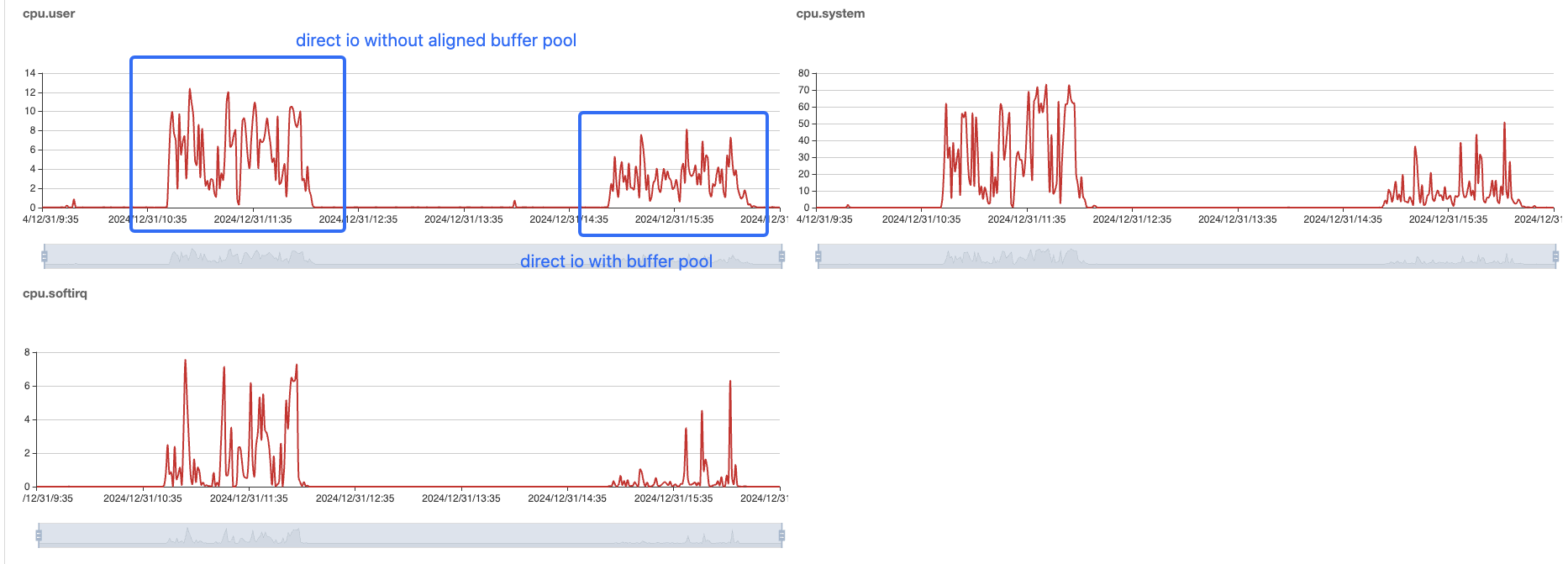
The cpu system user load is lower than the previous load without buffer pool, because the previous case cost too much time on request memory.
Small but effective optimization trick
When flushing the 10G big data into the file, you can split this operation into multi append operations to avoid requesting too large continuous memory region, that will burden the system load and slow down service.
Performance
The RPC latency of getting data from local disk
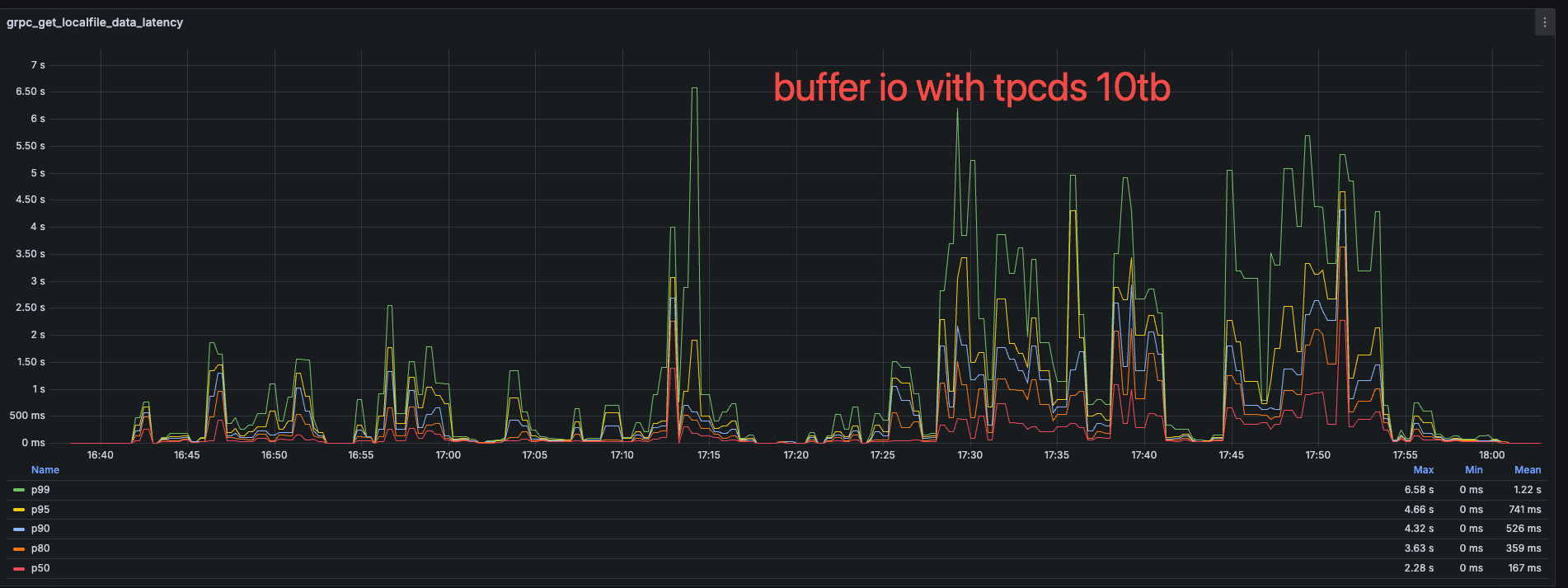
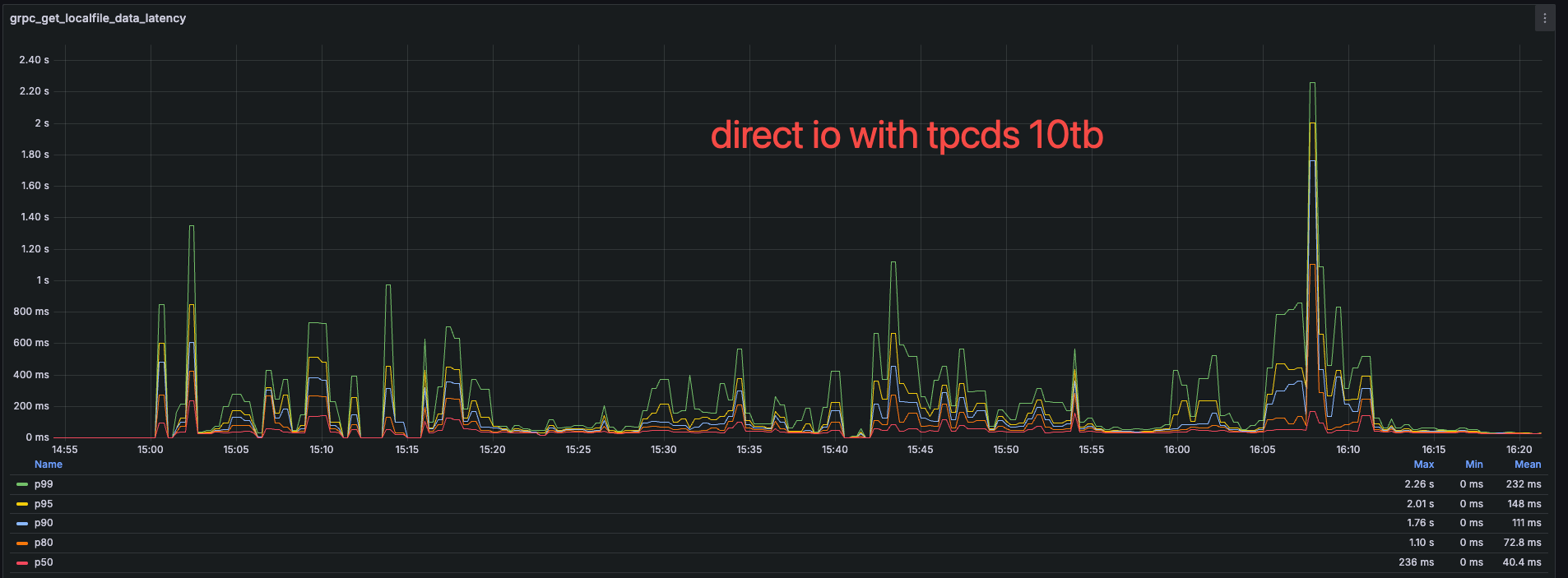
The RPC latency of sending data to memory
Due to the lower system load, the sending data latency on direct io will be more slower than the buffer IO.
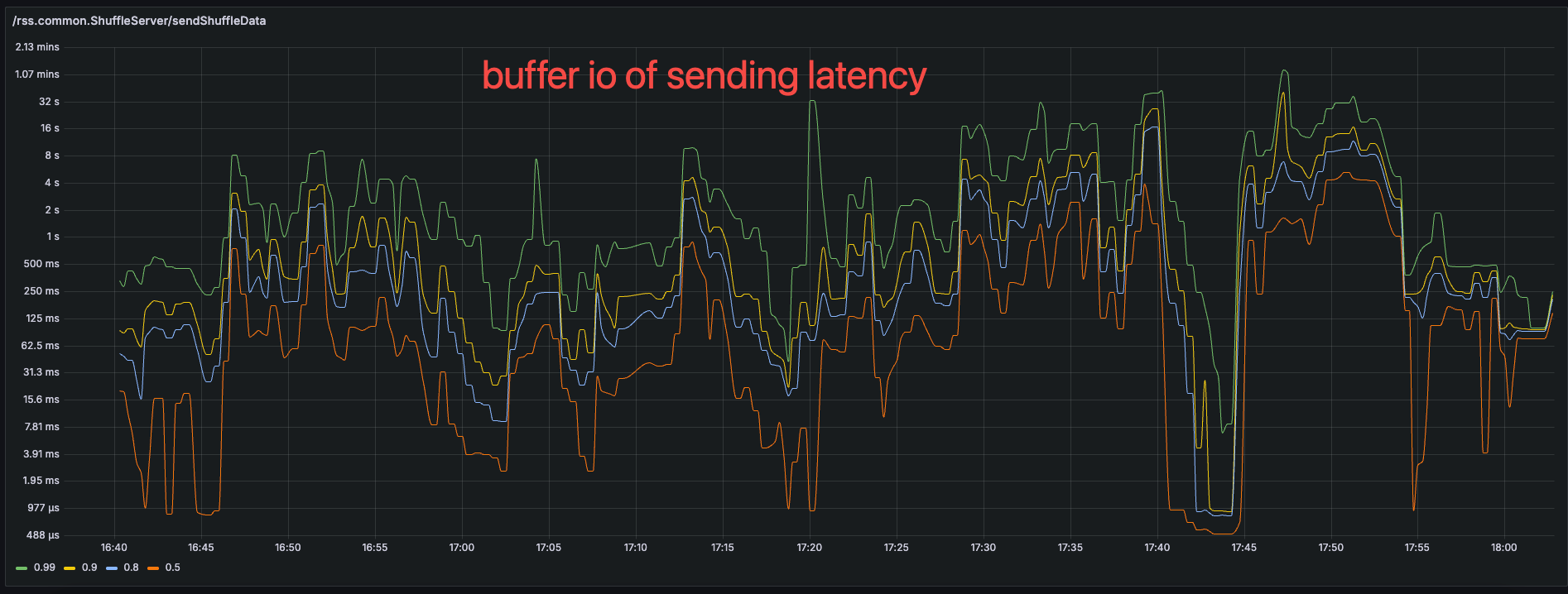
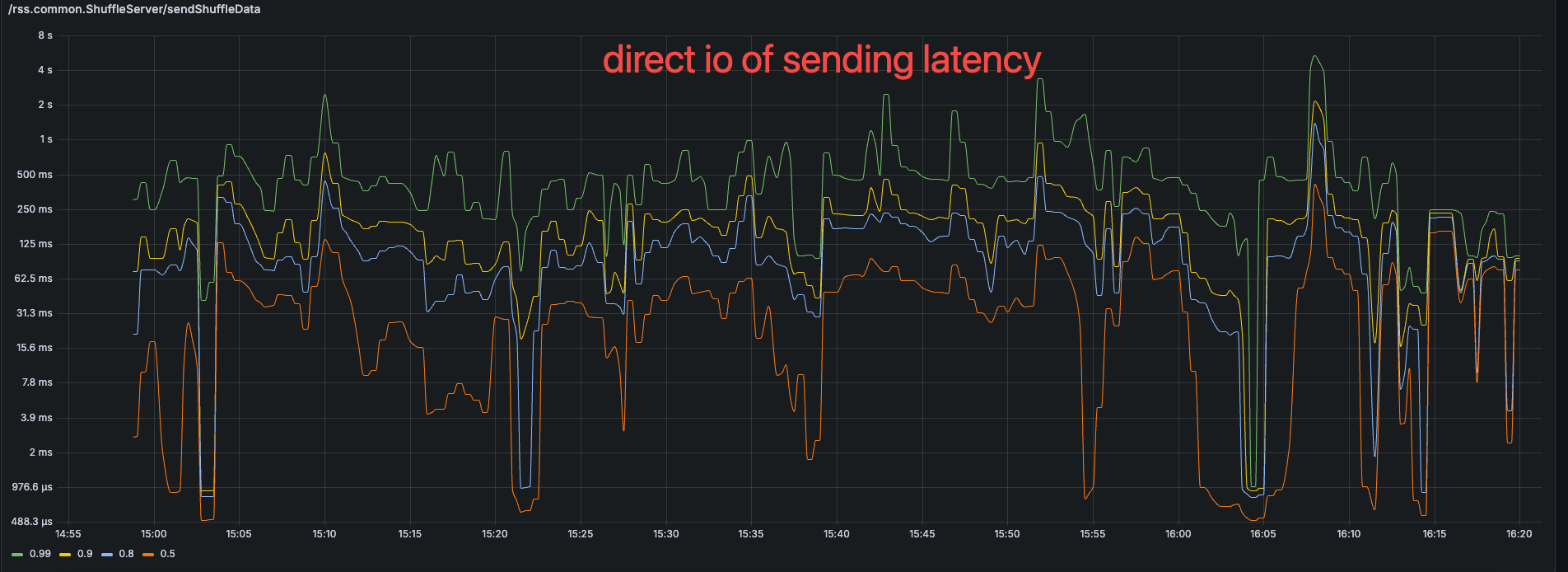
Now, it looks great!