Hadoop Yarn 扩展支持节点资源比例调度策略
#hadoop #yarn #asyncScheduling
背景
在使用 Yarn capacityScheduler 后,我们内部的 Hadoop3.2.2 版本 Yarn 也开启了异步调度。
因此本文将局限在 Yarn 开启异步调度后的一些功能扩展和 bug fix。
本文的缘起是由于我们 yarn 集群内部的计算节点非同质,有些节点是 96core, 有些是 256 和 64 核的。
我们观察到,在当前的 capacity scheduler 逻辑下,整个计算集群的水位线会率先压满 64 核的,而大核心的节点虽然已使用资源数逼近 64,但相较于整机的整体核心数比例还是非常低的。同时因为很多 64 核的节点,是和 datanode 混部的,如果 CPU 利用率持续处于高位,对于 datanode 服务也会产生一定的影响。
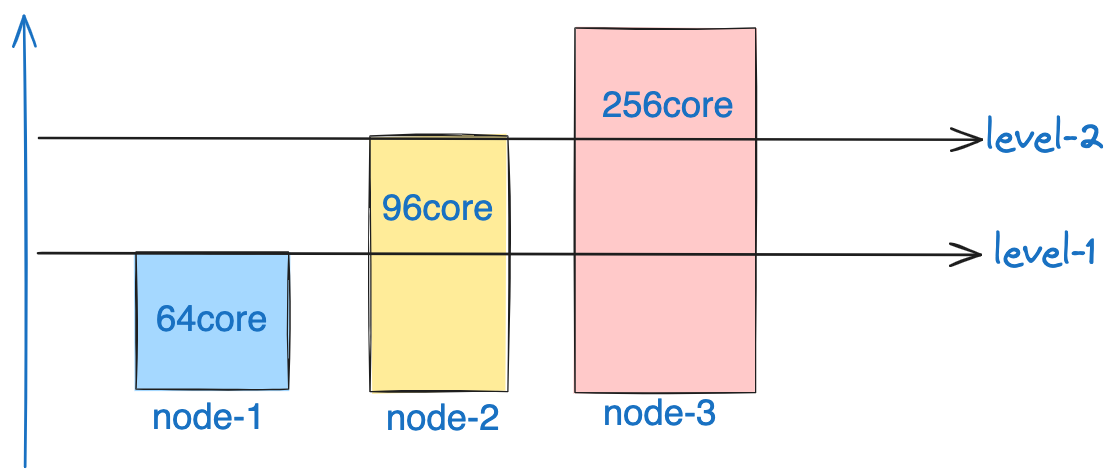
如上图所示,在默认的调度策略下,负载的水位线若是增加,则会自底向上运行,小的节点将会被压满,但是大容量节点则仍处于空闲的状态下。
基于此,我们想扩展下 Hadoop Yarn 的调度策略,从 round robin 的策略,改为根据节点自身资源比例来划分整体的节点排序调度策略。
什么是同步调度
在异步调度前,hadoop yarn 的调度是在 RM 接收到 Nodemanager 的 heartbeat 时触发,通过遍历队列 -> leaf queue 后,找到最优 app, 然后再找到最优的 container 来分配 (默认 NM 一次心跳,只做一次 container 分配,但开启参数后,可选择一次分配多个 container)。
整个调度逻辑是拿着 NM 来找分配的 container, 整个调度性能不是很好,如果未开启单次 heartbeat 进行多次 container 分配的逻辑,整个 Yarn 的 container allocation 的吞吐量受限于节点数和心跳的间隔。一秒的分配速率为:containerAllocationSecondRatio = nodeNumber / heartbeatInterval. (这还是假设分配不耗时的情况下的最好性能,但实际上节点越多,并发锁冲突越大,性能越差)
并且,每次的 container 分配调度没有全局视图,使得 app container 请求希望有一些亲和性的配置,是无法实现的。
Capacity Scheduler 异步调度
所谓异步调度,其实是由原先的 heartbeat 驱动改为 scheduler 使用线程池后台来并发驱动分配逻辑。在 capacity scheduler 当前的逻辑中,主要分为两个阶段,分别是 多线程提出提案 和 单线程接受提案。
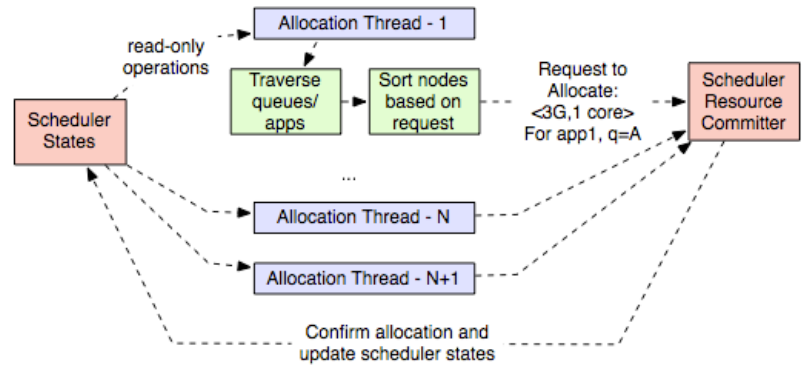
对于提出提案这个过程中,对于单个线程负责的内容来看,整体的逻辑如下图所示,分为如下几个步骤
- 根据 scheduler 拿到所有的 node,但是会被切成两部分,切的位点随机而定。先循环处理 batch2,再是 batch1. 这是为了在多线程情况下,减少冲突。
- 拿到具体的调度节点, 假设是 node5 后,先判断 node5 是否存在 reserved 的 container, 如果有,则优先分配此 container. 跳到步骤 4,分配完成后退出。如果没有,则进行步骤 3
- 会依次遍历队列,拿到最为优先的 container 请求。
- 尝试将 container 分配到 node5 上,会在 RegularContainerAllocator 进行节点与 container 请求的判断逻辑,包括 node attributes 以及 node partition 等要素,看是否匹配。匹配后,可进入下一步流程,不匹配则忽略如下的逻辑
- 在匹配上后,
- 如果当前节点资源不足,则会被 reserve (也就是 container 请求被 pin 到了此 node 上,理论上不做移动)。等待下一轮对此节点的调度,在下一轮中,会执行步骤 2 中 reserve 的流程。会产生 reserve 提案
- 如果资源充足,则会产生 allocated 提案
- capacity scheduler 中的线程拿到提案后,将其加入到 commit 队列,等待 committer service 进行 accept 和 apply
resource usage 策略
我们为了支持上述的 resource usage ratio 策略,需要使得异步调度的线程 task 对于一个 container 请求,能够拿到多个候选 node 来进行优先选择。
在我们的这个场景下,就是假设有 node1-node2-node3,当前的资源利用率分别是 50%-20%-30%,那么我们希望能将 container 优先分配到 node2 上。
经过对 Yarn 的代码走读 Yarn 异步调度代码走读,发现 yarn 已经插件支持了不同的调度策略。详见此参数:
<property>
<name>yarn.scheduler.capacity.multi-node-placement-enabled</name>
<value>true</value>
</property>
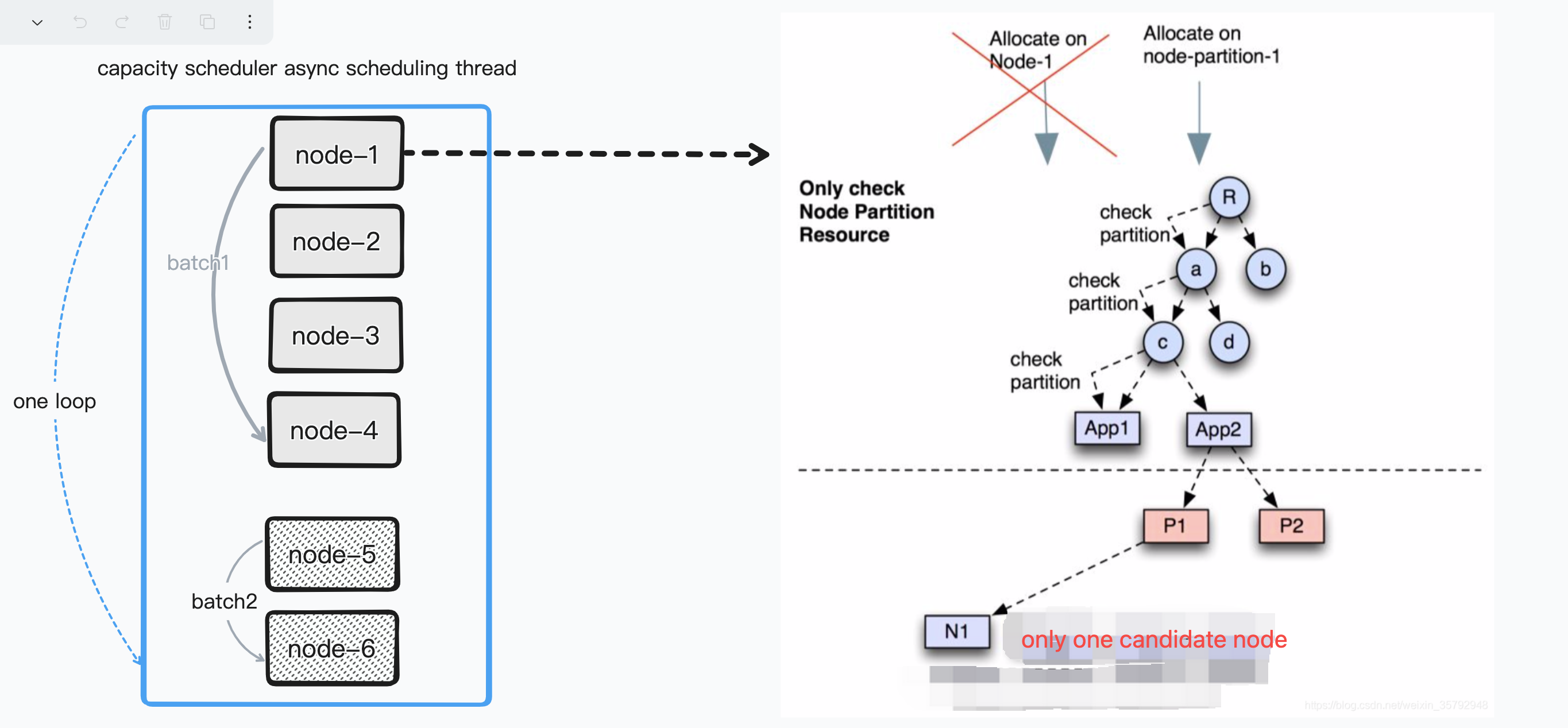
此参数一旦开启,则调度不再遵循上述的 round robin 的方式,也就是拿到所有的节点,依次对 node->container 进行匹配调度。会变成 (node1,node2,....nodeN) -> container,从候选节点集中选出最优的 node.
当前默认的策略实现是:ResourceUsageMultiNodeLookupPolicy, 也就是按照当前的资源使用量来进行选择,最低的则优先调度,但仍然不符合我们的需求。但是整体的插件化策略值得先学习下,便于实现自己的排序策略。
此插件化的 policy 会被 MultiNodeSortingManager 来进行管理,因为 policy 会涉及到排序,因此会在后台进行,默认的排序 interval 是 1 秒。同时 MultiNodeSortingManager 会在 AppPlacementAllocator 中会被调用,也就是 placement 的一些策略的实现类中。梳理下,整体的多节点调度的层次关系如下:
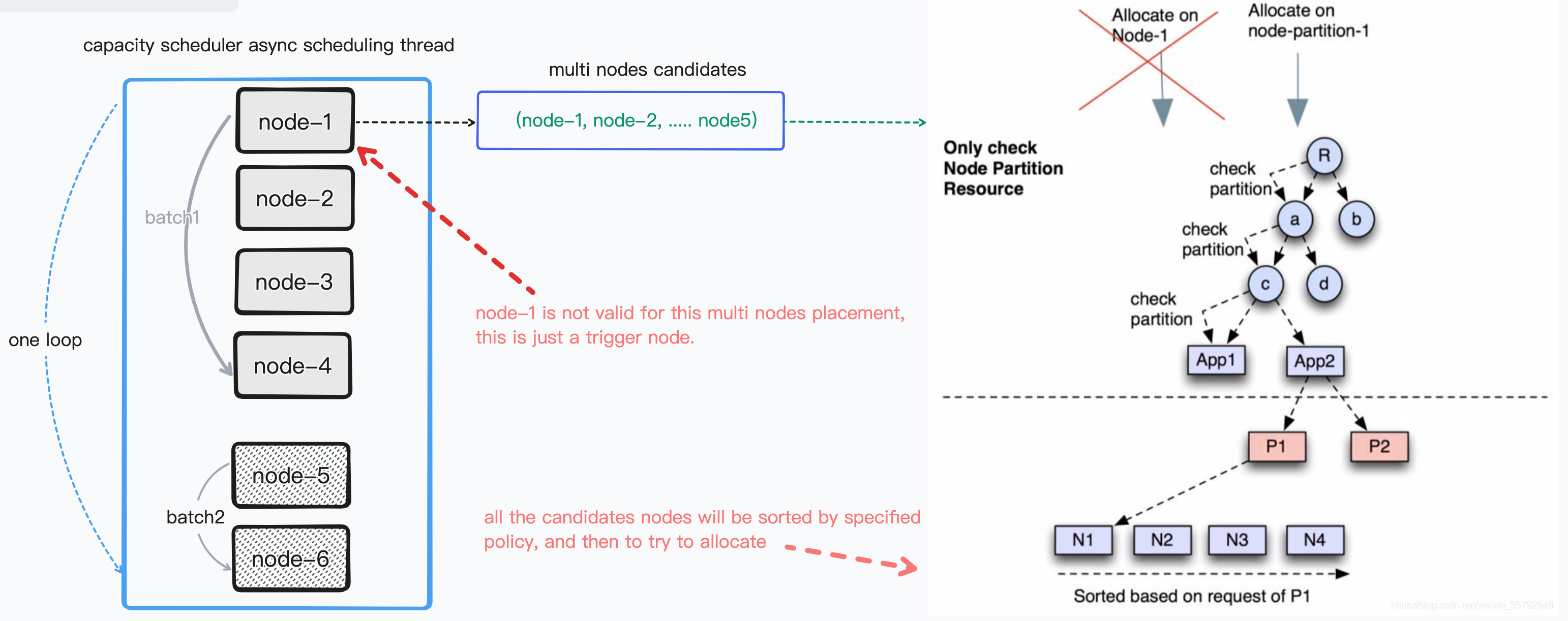
在 container 被选出后,会拿到 sorted 的 candidate nodes 来依次判断是否满足条件,一旦满足,则立即退出,并提交提案。(tips: reserve 也属于条件满足)。
当对于此 policy 进行测试时(使用的参数如下), 发现有 app 的请求无法得到满足,但集群的资源远大于 app 的请求量。
<property>
<name>yarn.scheduler.capacity.multi-node-placement-enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.capacity.multi-node-sorting.policy.names</name>
<value>default</value>
</property>
<property>
<name>yarn.scheduler.capacity.multi-node-sorting.policy</name><value>default</value>
</property>
<property>
<name>yarn.scheduler.capacity.multi-node-sorting.policy.default.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.placement.ResourceUsageMultiNodeLookupPolicy</value>
</property>
经过对 RM jstack(猜测线程一直在执行某个无效操作) 以及代码研读,发现整个异步调度逻辑被卡在了 提出提案的步骤 2 上. RM 日志中也描述了这一点 :
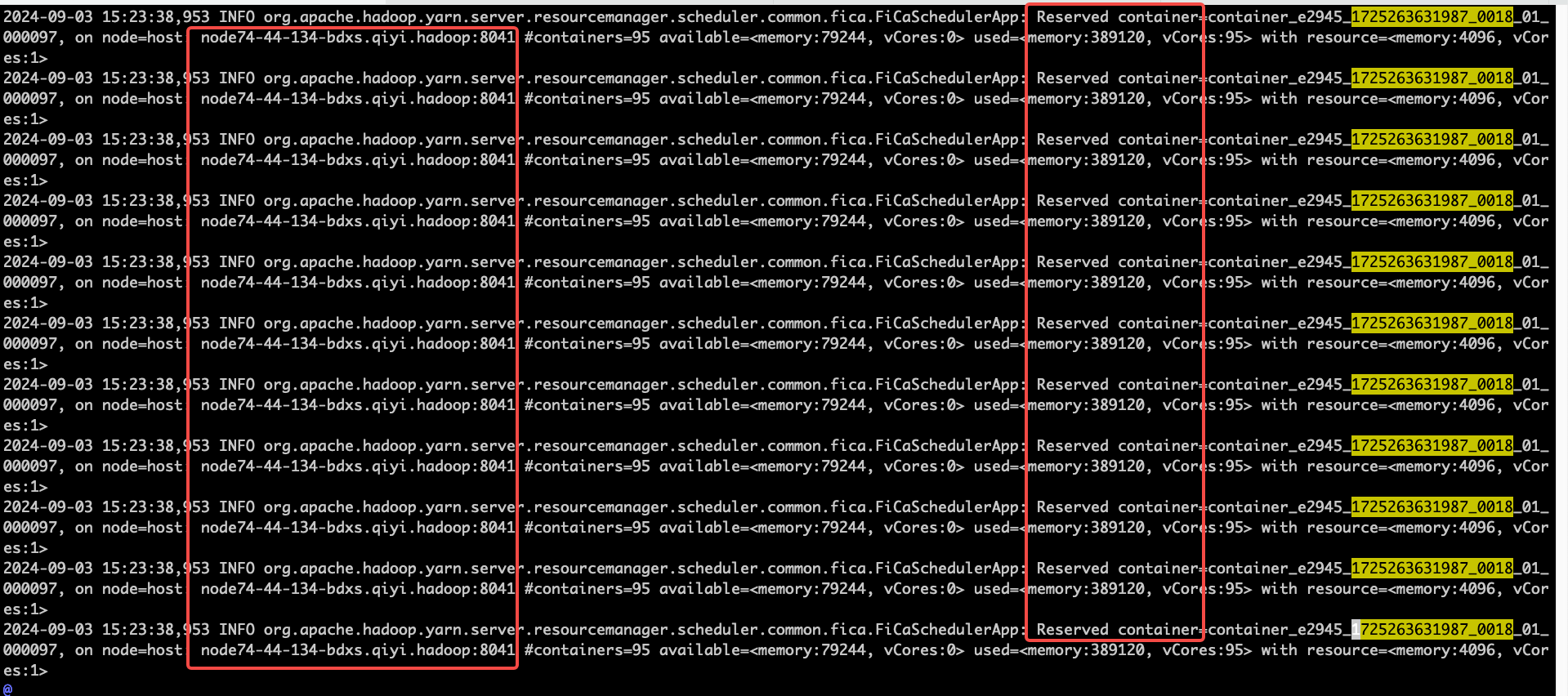
所有的线程都一直在对 reserve 的节点进行再次分配, 且一直在对 container 00097 进行分配,后续的 300 多个 container 请求未进行触发分配。这部分代码,主要的逻辑在:LeafQueue.allocateFromReservedContainer 用来优先给 reserved 来进行分配 。触发的代码如下:
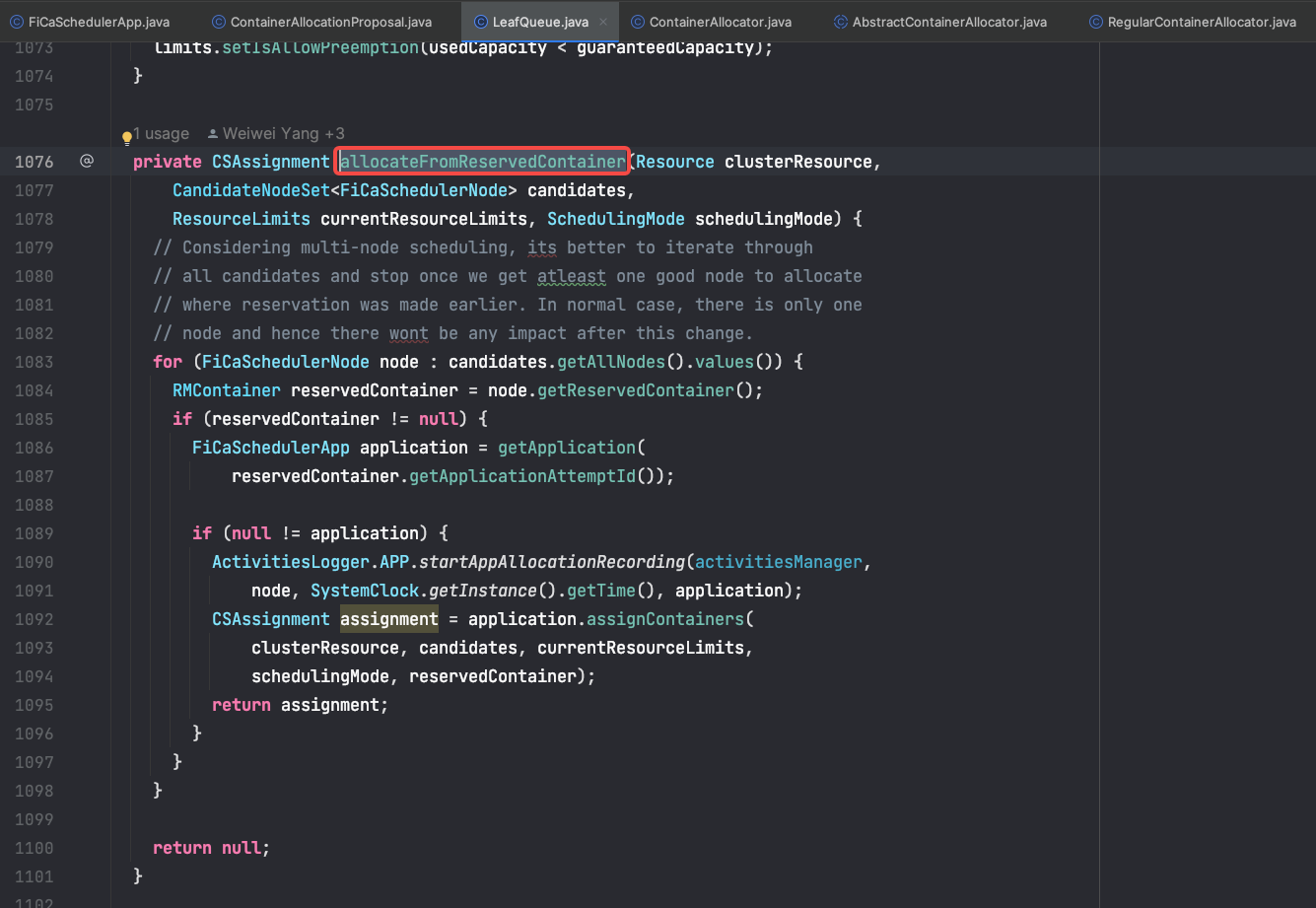
这段代码有几个问题:
- 一旦候选集中某个节点存在 reserved container, 则多个线程会去同时执行对 reserve container 的再判断逻辑,降低了整体的调度吞吐量
- 如果此时 reserve 节点和 node 仍然资源不满足,则 reserve 的 container 不会被其他有资源的节点 pick up. 相当于一直 pin 在此 node 上。截止目前,我没有发现 Yarn 有 pick up 长时间未分配的 reserved container 的机制
但是上述的问题,本质上不会导致整体调度逻辑的卡住。因为我们的 candidates nodes 列表会在 1 秒内进行刷新,如果有 reserved container,理论上也会被其他有资源的节点进行 pickup,但为什么我们观察到 container 请求不被分配呢?
仔细分析后,结论如下:
- 因为开启了 resource usage 的策略后,app 请求分配的 400 个请求在第 96 个时候卡住了, 此时 resource usage 排序的 top1 节点的总资源数是:95. 因此第 96 个 container 请求被 reserve 了
- 当步骤 1 发生后,上述的代码一直在进行对 reserve 的 container 再分配,此时如果已经超过了 1s,resource usage 再次触发排序,因为 reserved container 与其他有资源节点进行了提案
- 提案被接收后,committer service 再进行处理。发现此 container 是从另外一个节点 reserve 后再被分配的,直接被拒绝了!拒绝的代码如下
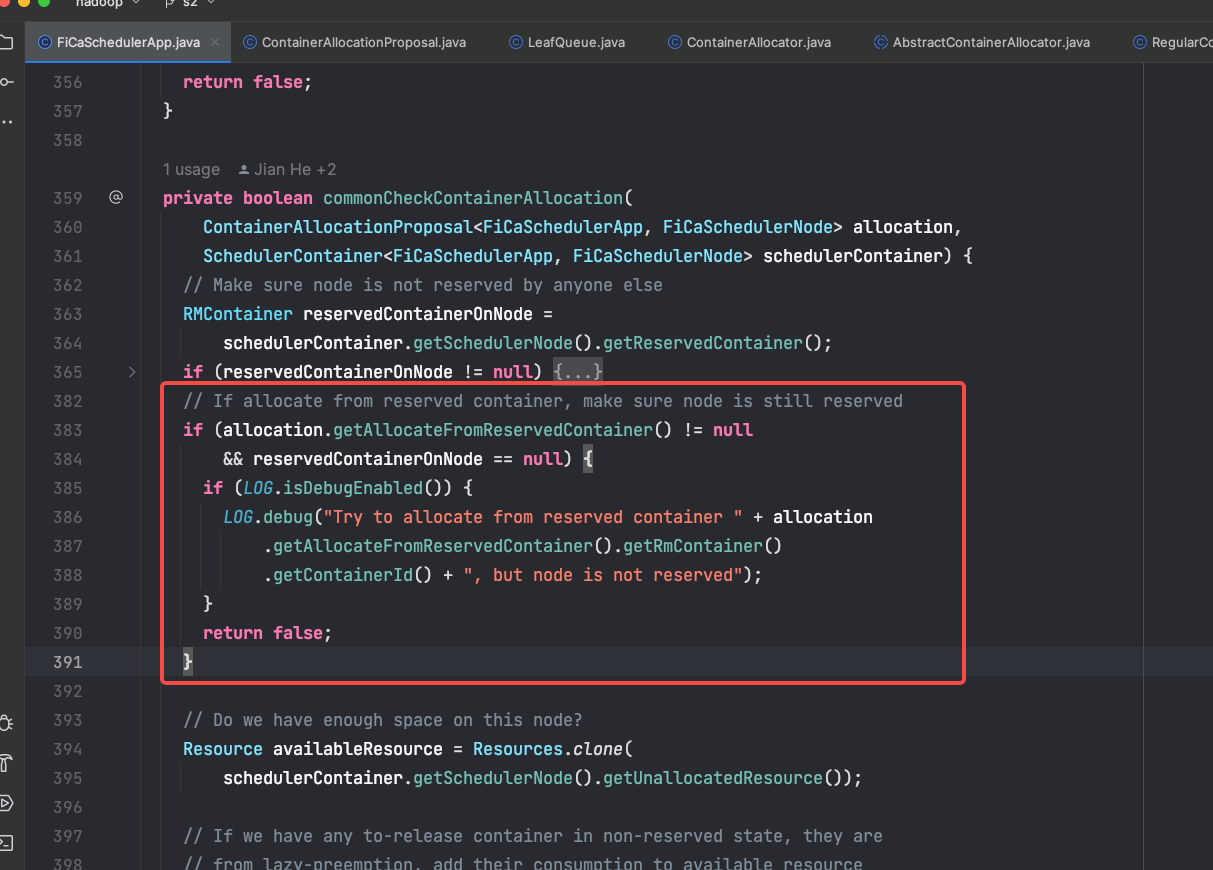
此段代码是由于 YARN issue: https://issues.apache.org/jira/browse/YARN-8127 引入的,为了解决并发对 reserve container 提交造成 resource leak, 也就是类似于上述的问题 1.
分析下代码:
- allocation.getAllocateFromReservedContainer() != null 此条件,是如果 container 是从 reserved 中再次调度后,资源得到满足后 allocated 状态后,是不会为 null 的
- reservedContainerOnNode==null 是说明待调度的节点上无 reserve 资源。
上述的两个条件,在未开启 multi node placement 时,确实是解决了多个 reserve->node 上的冲突问题。但是对于 multiple node placement,reserved container 会被转移,导致一旦转移到了一个非之前 reserved 的节点时,则永远会被判定为 false. 因此提案会被 reject.
在拿到问题的关键点后,提出如下的解决方案
- 修改源码,使得 yarn 允许 reserved container 的再次分配 --> 根本性解决 reserved container 无法被 pickup 的问题
- 对于一个 container 来说,如果有其他的候选者,则忽略 reserve 的情况,直到资源被满足。如果都不满足,则再 reserve. --> 避免在多个候选者下的资源 reserve,再被饿死
具体的两种方案的修改,详述如下
Yarn 支持 reserved container 再被其他节点分配
经过代码研究发现,reserved container 再被其他节点分配这个机制,在 yarn 中是不支持的。因此需要修改一定的代码,修改的 diff 待提交到 YARN 社区
这个 feature 在这里简称为 reserved container pick up。
当有多个 candidate node 情况下,忽略已经 reserve
hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-resourcemanager/src/main/java/org/apache/hadoop/yarn/server/resourcemanager/scheduler/capacity/allocator/RegularContainerAllocator.java
对此类,增加如下的代码:
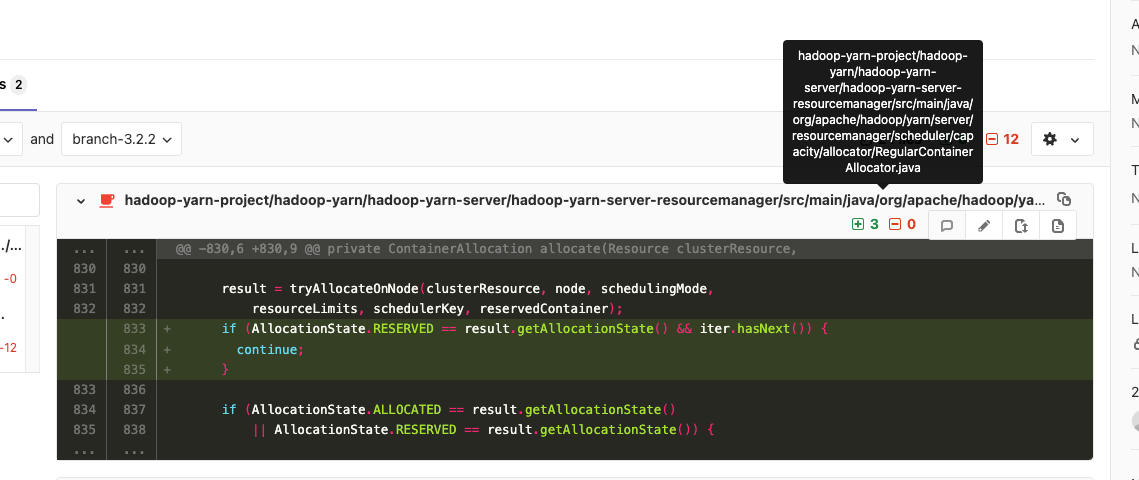
2024-11-04: 通过浏览 hadoop yarn issues, 发现 https://issues.apache.org/jira/browse/YARN-11573 修复了类似的 bug,已经在 hadoop3.4.0 版本上进行了应用。但是很奇怪,此 patch 在默认情况下被关闭。
2024-12-25: 目前来看,最新版本的 hadoop 已经修复 reserve 导致卡住的问题。详见以下的 issue
Resource usage ratio 策略的实现
至于如何实现自定义的 resource usage ratio 策略,则在此不详述,类比 resource usage 策略即可。
借助的排查手段
- IDEA remote JVM debug,最为方便,但是 JVM 会挂掉
- arthas hack 进 JVM 内部来查看某些变量的值
- 日志!最为简陋以及最不方便
可能的 YARN improvement
- Default policy class 没能在队列上默认配置,还是需要显式配置
- multi node placement 存在 reserve 导致 app 饿死的 bug,需要修复