iQIYI Big Data Hybrid OnPremise and Cloud Deployment
#iqiyi #hadoop #bigdata #onPremise #cloud
As the main developper, this hybrid cloud framework benefits from the koordinator + Uniffle + Hadoop Yarn.
Mixed deployment, as a strategy to enhance resource efficiency and reduce costs, is broadly recognized by the industry. In its journey towards cloud nativity and cost-effectiveness, iQIYI has successfully mixed-deployed workloads such as big data offline computation and audio-video content processing with its online services, achieving incremental benefits. This article, taking big data as an example, delves into the practical process of implementing a mixed deployment system from ground zero to completion.
Background
iQIYI’s big data supports critical scenarios within the company, such as operational decision-making, user growth, ad distribution, video recommendation, search, membership, and more, providing a data-driven engine for the business. With the growth of business demands, the volume of resources needed for computation increases daily, posing significant pressure on cost control and resource supply.
iQIYI’s big data computation is divided into two processing streams: offline computation and real-time computation. Among them: Offline computation includes Spark-based data processing, hourly to daily data warehouse construction primarily using Hive, and the corresponding report query analysis. Such computations typically start in the early hours of the day to process the previous day’s data and finish in the morning. The peak period for computational resource demand is from midnight to 8 A.M., during which the cluster often falls short of total resources, leading to queuing and backlog of tasks, while significant idle periods during the day result in resource wastage.
Real-time computation consists of real-time data stream processing, represented by Kafka + Flink, which has a relatively stable resource demand.
To balance the utilization of big data resources, we have mixed-deployed offline and real-time computations, which has alleviated the waste of idle resources during the day to some extent, but still fails to effectively smooth the peaks and fill the valleys of demand. The overall utilization of big data computing resources still exhibits a tidal phenomenon with low demand during the day and high peaks in the early morning. As shown in the figure-1 below

Figure 1. CPU Usage Variation within a Big Data Computing Cluster Over a Single Day
iQIYI’s online services face another issue: balancing service quality with resource utilization. Online services primarily cater to scenarios such as iQIYI’s video streaming, with more users watching videos during the noontime and evening, resulting in a “daytime peak, early morning valley” tidal pattern in resource usage (as shown in Figure 2). To ensure service quality during peak times, online businesses typically reserve a considerable amount of resources, which leads to a very suboptimal resource utilization rate.

Figure 2. CPU Usage Variation in Online Business Cluster Throughout a Day
To improve utilization rates, iQIYI’s self-developed previous generation container platform adopted a CPU static overcommit strategy. Although this approach had a noticeable effect on improving utilization, it was limited by kernel capabilities and other factors, and could not avoid occasional resource competition between services on the same machine, leading to instability in the quality of online service. This problem has never been properly resolved.
With the advancement of cloud-native transformation, iQIYI’s container platform gradually shifted to the Kubernetes (hereafter referred to as “K8s”) technology stack. In recent years, multiple open-source projects related to hybrid deployment have emerged in the K8s community, and some hybrid deployment practices [1] have been developed within the industry. Against this backdrop, the Compute Platform team pivoted their focus from “static overcommit” to “dynamic overcommit + hybrid deployment.”
Big data, as the most typical offline business, has been the forerunner in attempting to implement hybrid deployment. On one hand, big data has significant volume and relatively stable computational resource demands; on the other hand, big data operations can complement online services in many dimensions. Through hybrid deployment, resource utilization can be greatly improved.
Based on the above analysis, the iQIYI Compute Platform team and the Big Data team began to explore hybrid deployment.
Hybrid Deployment Solution Design
iQIYI’s big data ecosystem is built upon the open-source Apache Hadoop framework, with YARN employed as the computational resource scheduling system. On the other hand, online services are built on Kubernetes (K8s). A key challenge for hybrid deployment is bridging these two disparate resource scheduling systems.
There are typically two approaches in the industry for hybrid deployment: Approach 1: Directly run big data jobs (e.g., Spark, Flink, excluding MapReduce) on K8s using its native scheduler. Approach 2: Run YARN’s NodeManager (hereafter referred to as “NM”) on K8s, with big data jobs still scheduled through YARN.
After careful consideration, we chose the second approach for the following reasons:
- The majority of our big data computing jobs are currently scheduled through YARN, which has a strong scheduling capability (multi-tenant multi-queue, rack awareness), excellent performance (over 5k containers/sec), and a robust security mechanism (Kerberos, Delegation Tokens), supporting nearly all big data compute frameworks like MapReduce, Spark, and Flink. Since first introducing YARN in 2014, the iQIYI big data team has built a series of platforms around it for development, maintenance, and computing governance, providing a convenient big data development workflow for internal users. Therefore, compatibility with the YARN API is one of the important considerations for choosing a hybrid deployment approach.
- Although K8s has batch schedulers, they are not mature enough and their scheduling performance has bottlenecks (<1k containers/sec), falling short of the requirements for big data scenarios.
At the K8s level, both parties need a standard interface for managing and utilizing hybrid deployment resources. There are many excellent projects in the community, such as Alibaba’s open-source Koordinator [2], Tencent’s FinOps project Crane [3], and ByteDance’s open-source project Katalyst [4]. Among them, Koordinator has a “natural” adaptability with DragonflyOS (one of the CentOS replacement options iQIYI is trying), which can work together to achieve online business load monitoring, idle resource over-allocation, graded task scheduling, and QoS guarantee for online-offline workloads, meeting iQIYI’s needs.
Based on the above technical selection, we deeply reformed and containerized YARN NM to run in K8s Pods. It can sense in real-time the dynamically changing overallocated computing resources from Koordinator, enabling automatic horizontal and vertical scaling to maximize the use of hybrid deployment resources.
Evolution of Hybrid Deployment Scheduling Strategy
The hybrid deployment of big data and online services has undergone several stages of technical evolution, which we will detail below.
Phase 1: Nighttime Time Division Reuse To quickly verify the solution, we first completed the containerization transformation of NM on K8s Pods (without adopting Koordinator at this stage), serving as elastic nodes to expand the existing Hadoop cluster. At the big data level, these K8s NMs are uniformly scheduled by YARN, along with NMs on other physical machines. These elastic nodes are scheduled to start and stop daily and operate only between midnight and 9 am.
During this phase, we completed more than 20 modifications. Below are 5 major points of modification.
Modification Point 1: Fixed IP Pool Traditional
NMs are deployed on physical machines with fixed IPs and hostnames, and a node whitelist (slaves file) is configured in YARN ResourceManager (hereafter referred to as “RM”) to allow the node to join the cluster. At the same time, the YARN cluster utilizes Kerberos for secure authentication; before deployment, keytab files must be generated at the Kerberos KDC and distributed to NM nodes.
To adapt to YARN’s whitelist and security mechanisms, for our self-built clusters, we employed our self-developed static IP functionality. Each static IP has a corresponding K8s StaticIP resource to record the relationship between the Pod and the IP. Based on the public cloud cluster, we also deploy our self-developed StaticIP CRD and create StaticIP resources for each static IP. This provides a fixed IP pool for YARN with the same usage method as the self-built clusters. Based on the IPs within the fixed IP pool, we create DNS records and keytab files in advance, allowing NM to quickly access the required configurations upon startup.
Modification Point 2: Elastic YARN Operator
To render the introduction of elastic nodes transparent to the users, we added flexible NMs to the existing Hadoop YARN cluster. Considering the later complexity of dynamic resource awareness for hybrid deployment, we chose our self-developed Elastic YARN Operator to better manage the lifecycle of elastic NMs.
At this stage, the policies supported by Elastic YARN Operator include:
On-demand start-up: to respond to sudden offline task traffic, including summer and winter holidays, public holidays, significant events, etc.
Cyclical on-off: taking advantage of online services’ resource utilization lows in the early morning, big data tasks can run.
Modification Point 3: Node Label — Isolation of Elastic and Fixed Resources
Real-time big data stream computing tasks like Flink run non-stop 24/7 and require higher stability from NMs than batch jobs do; auto-scaling of elastic NM nodes or resource adjustments can lead to task restarts, causing real-time data fluctuations. To address this, we introduced the YARN Node Label feature [5], dividing the cluster into fixed nodes (physical machine NM) and elastic nodes (K8s NM). Batch jobs can use any node type, while stream jobs can only run on fixed nodes.
Furthermore, the basis of batch job fault tolerance is the stability of the YARN Application Master. Our solution added a new configuration to YARN, specifying the default label to be used by the Application Master, ensuring it is not assigned to elastic NM nodes. This functionality has already been merged into the community: YARN-11084, YARN-11088.
Modification Point 4: NM Graceful Decommission
We adopted a fixed schedule for bringing elastic nodes online and offline to balance online-offline resource use. Elastic NM starts up are initiated by the YARN Operator; once started up, tasks can be scheduled. Decommissioning elastic NMs is slightly more complex, as tasks still run on them, and we need to ensure tasks have completed within the schedule.
For example, our cyclical deployment strategy is: elastic NM comes online from midnight to 8 am; the decommissioning period is from 8 am to 9 am, and the nodes are offline from 9 am to midnight. By using YARN graceful decommission [6], we prevent incremental container requests from being allocated to decommissioning nodes, allowing tasks to slowly conclude within the decommissioning period.
However, in our clusters, most batch tasks are Spark 3.1.1. Spark uses YARN containers as task executors, and in most cases, a 1-hour decommissioning window is not enough. Thus, we introduced several optimizations from SPARK-20624 [7], allowing executors to respond to YARN decommission events and exit as quickly as possible.
Modification Point 5: Introduce Remote Shuffle Service — Uniffle
Shuffle is a crucial component of offline tasks. Traditionally, we use the Spark ESS deployment model on NodeManager. However, with the introduction of elastic nodes featuring short lifecycles, we cannot ensure that shuffle data on nodes are consumed within the YARN graceful decommission period, leading to overall job failures.
We introduced Apache Uniffle (incubating) [8] to implement a remote shuffle service, decoupling Spark shuffle data from NM lifecycle. NM was transformed into a purely computational role, not storing intermediate shuffle data, thus achieving fast and smooth NM decommission.
On the other hand, the cloud disks mounted by elastic NM generally show mediocre performance and cannot withstand high IO and high concurrency random reads/writes, which would also impact online services. By building a high-performance IO-specific Uniffle cluster, we deliver faster shuffle services.
As a deep participant in Uniffle, iQIYI contributed over 100 improvements and 30+ features, including Spark AQE optimizations [9], support for Kerberos [10], and super-large partition optimizations [11], among others.
Phase 2: Resources Overallocation
In phase one, we achieved an initial hybrid deployment using only the unallocated surplus resources in the K8s resource pool. To maximize idle resource usage, we introduced Koordinator for resource overallocation.
We imposed fixed specifications on the resource capacity of elastic NMs: 10 cores of batch-cpu and 30 GB of batch-memory (batch-cpu and batch-memory are extended resources overallocated by Koordinator), ensuring offline task resources do not exceed these limits.
To ensure the stability of online services, Koordinator suppresses CPU for offline tasks [12]. Suppression results are determined by the difference between the suppression threshold and the actual usage of online service CPUs (not request amounts). This difference represents the maximum CPU resources available for offline business; given the constant change in online business CPU actual usage, the CPU resources available for offline use are continuously changing, as shown in Figure 3:
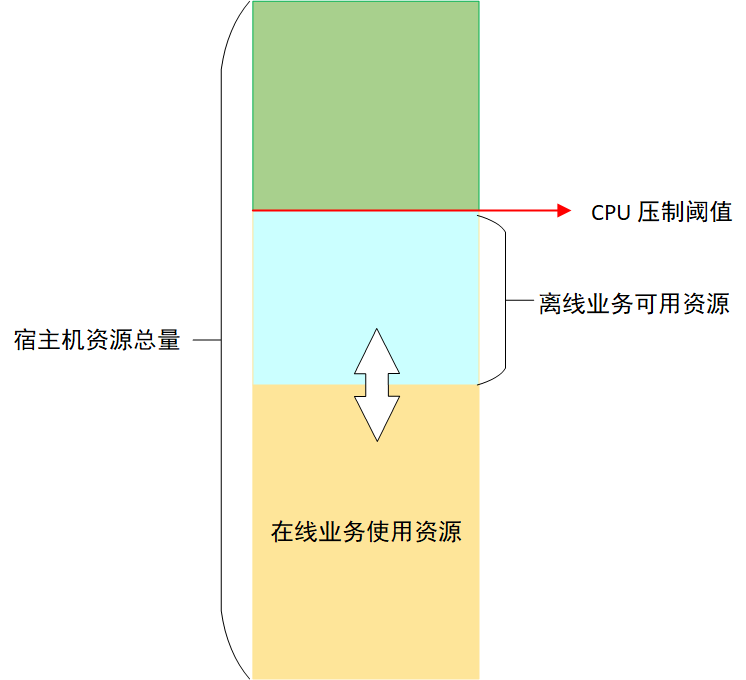
Figure 3. Koordinator resource allocation strategy
Suppressed CPU for offline tasks ensures online service stability but elongates offline task execution times. If suppression is severe on a particular node, it might lead to wait times, slowing overall task execution speed. To prevent this, Koordinator offers CPU satisfaction-based eviction [13]. When CPU used by offline tasks is suppressed below a user-specified satisfaction level, eviction of offline tasks is triggered. Once evicted, tasks can be scheduled on machines with ample resources, avoiding wait times.
After a period of testing and verification, we found that online business ran stably, and the average 7-day CPU utilization of clusters increased by 5%. However, NM Pods on nodes were sometimes evicted. Once NM is evicted, RM cannot immediately detect the event, leading to delayed task rescheduling. To address this issue, we developed a feature for NM to dynamically detect node offline CPU resources.
Phase 3: From Nighttime to All-Day Real-Time Elasticity
Rather than triggering Koordinator’s eviction operation, it would be better for NM to proactively detect changes in offline resources on the node, scheduling more tasks when offline resources are sufficient and stopping task scheduling or even actively killing some offline container tasks when resources are insufficient, to avoid NM eviction by Koordinator.
With this idea, we utilized YARN Operator to dynamically sense the resources available to the node for vertical scaling of available NM resources. This is done in two steps: 1) provide the CPU suppression metric for offline tasks; 2) enable NM to perceive CPU suppression and take measures, as shown in Figure 4:
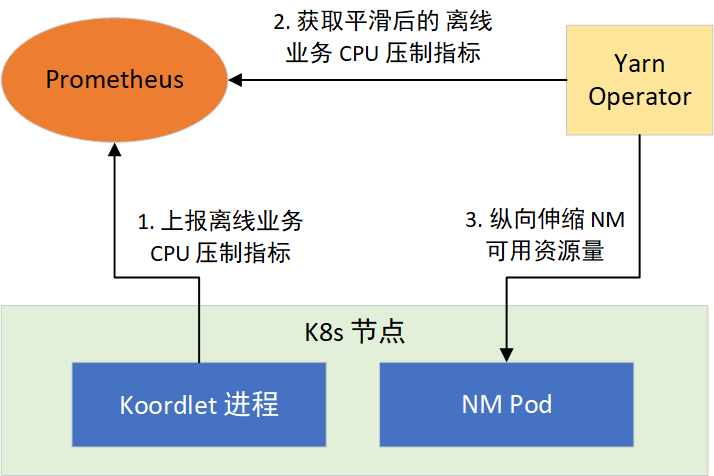
Figure 4. NM dynamically detects resources
CPU Suppression
Metric Koordinator’s Koordlet component runs on K8s nodes, executing CPU suppression, Pod eviction, and other operations. It provides CPU suppression metrics in Prometheus format, which can be externally provided through Prometheus after collection. CPU suppression metrics are updated every second by default and fluctuate with changes in online business loads. Since Prometheus metric scraping cycles are generally longer than 1 second, some data loss occurs. To smooth fluctuations, we modified Koordlet to provide 1 min, 5 min, 10 min averages, variances, max, and min values of the CPU suppression metric for NM to choose from.
YARN Operator Dynamical Perception and Vertical Scaling
In the NM’s permanent deployment mode, the YARN Operator provided new strategies. It receives metrics on resources available on the currently deployed node within 10 minutes and uses this data to decide whether to scale the NM on the host machine vertically.
For scaling up, as soon as resources exceed 3 cores, a node resource update is requested from RM. The scaling-up process is shown in Figure 5:

Figure 5. NM dynamically scales up resources
Conversely, we ignore fluctuations within a 10% suppression rate by default. If the suppression rate exceeds the threshold, a scale-down operation is triggered, in two steps: 1) update the node’s available resources in RM to block incremental container allocation demand; 2) send the scale-down request to the NM guarder sidecar container for smooth and forced offline of containers using excessive resources, preventing eviction of the entire NM due to excessive CPU usage.
Once the target resources are determined, the guarder ranks all YARN container processes, considering framework type, runtime, and resource usage to decide on processes to terminate. Before killing, a SIGPWR signal is sent for smooth task termination. Spark Executors on receiving this signal will exit as smoothly as possible. The scale-down process is illustrated in Figure 6:
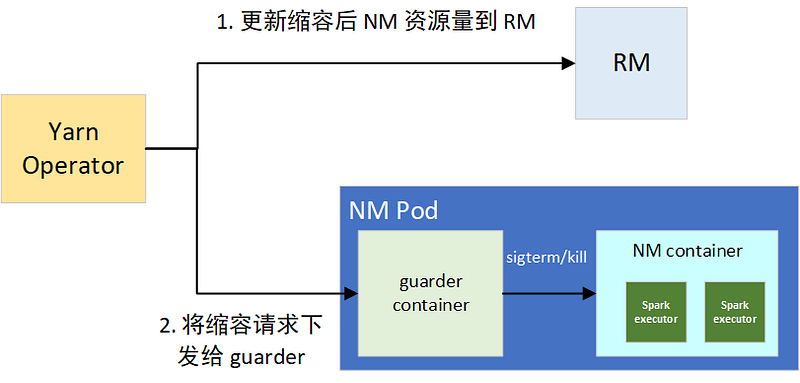
Figure 6. NM dynamically scales down resources
Generally, the variation in node resource amounts is not significant, and NM’s available resources maintain a high level (an average of 20 cores), with some container lifespans in the tens of seconds. So, target resource amounts are rapidly achieved. For nodes with frequent changes, smooth offline and killing decisions by guarder lead to very few container failures. From our online observations, the average daily count of forcefully killed containers is about 5, and there are 500+ smooth offline signals sent by guarder, indicating good results.
After the offline CPU resource awareness functionality fully launched, NM Pod evictions essentially ceased. We gradually extended the hybrid deployment window from the initial 0 am to 8 am to run 24 hours all day. We applied different CPU overallocation ratios throughout the day based on online business load distribution, hence achieving an all-day real-time elasticity scheduling strategy. With stable 24-hour operations, the cluster CPU utilization rate increased by another 10%. Observing the mixed K8s cluster from online deployments (as shown in Figure 7), the vcore use of elastic NMs (green line) dynamically aligns with overallocatable resources (yellow line).

Figure 7. Hybrid resource allocation and usage
Phase 4: Increasing Resource Overallocation Rate
To offer more offline resources, we began slowly raising the CPU overallocation ratio, and this led to NM Pods being evicted again — this time due to memory eviction. We set the memory overallocation rate of physical machines to 90%. Viewing the overall stature of the cluster, the physical machine memory resources were ample. Initially, we only focused on CPU resources without paying heed to memory. Yet, with a 1:4 ratio of CPU to memory usage in NM, as the CPU overallocation rate rose, so did YARN task memory requirements. In the end, when K8s node memory usage exceeded the set threshold, it triggered Koordinator’s eviction operation.
Upon observation, we found that memory eviction occurred with higher probability on specific nodes. These nodes had less memory than others while maintaining the same CPU count. Thus, under the same CPU overallocation ratio, these nodes were more susceptible to eviction due to memory, offering less offline memory. As such, the guarder container also needed to be aware of node offline memory resource usage and take corresponding actions based on the usage — similarly to how it handles offline CPU resources, which need not be reiterated.
After rolling out memory awareness, we incrementally increased the CPU overallocation ratio again. The online business cluster’s average daily CPU utilization rate has since climbed to 40%+, with 58% at nighttime.
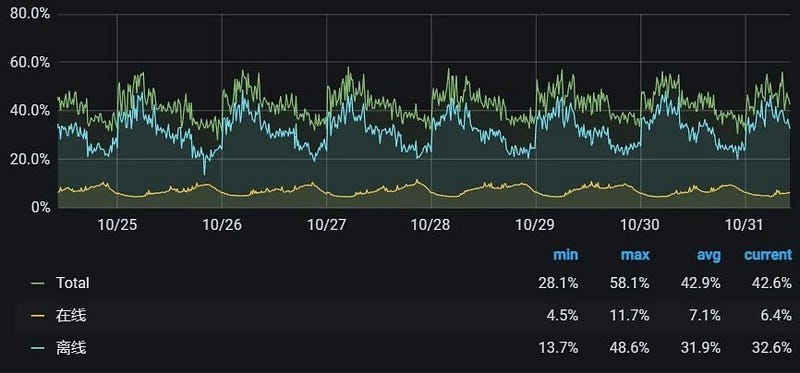
Figure 8. Hybrid cluster CPU utilization
Effects
Through the hybrid deployment of big data offline computing and online business, we increased the average CPU utilization of the online business cluster from 9% to over 40%, meeting some big data elastic computing resource demands without additional machine procurement and saving tens of millions in costs each year.
Simultaneously, we also applied this framework to big data OLAP analysis scenarios, realizing an elastic architecture for Impala/Trino on K8s. This satisfies the daily dynamic query requirements of data analysts while supporting temporary large-scale resource expansion during significant events like summer and winter vacations, Spring Festival Gala live streaming, and advertising during sales events like June 18th (618) and Double 11 (Singles Day). This ensures stability and efficiency in ad, BI, membership, and other data analysis scenarios.
Future Plans
Currently, big data online-offline hybrid deployment has been running stably for over a year and has achieved staged results. In the future, we intend to further promote big data cloud-native transformation based on this framework:
- Enhancing observability in online-offline hybrid deployment: Establish precise QoS monitoring to ensure the stability of both online services and big data elastic computing tasks.
- Intensifying online-offline hybrid deployment efforts: On the K8s level, continue to improve the host machine resource utilization rate to provide more elastic computing resources for big data use. From the big data perspective, further increase the proportion of elastic computing resources scheduled through the online-offline hybrid deployment framework to save more costs.
- Hybrid cloud computing for big data: Currently, we mainly use iQIYI’s internal K8s for hybrid deployment. However, as the company advances its hybrid cloud strategy, we plan to extend the hybrid deployment to public cloud K8s clusters and achieve multi-cloud scheduling for big data computation.
- Exploring cloud-native hybrid deployment models: While reusing YARN’s scheduler has allowed us to quickly tap into hybrid deployment resources, it has also introduced additional resource management and scheduling overheads. We will also explore cloud-native hybrid deployment models, attempting to schedule big data computing tasks directly using K8s’s offline schedulers, further optimizing scheduling speed and resource utilization.
Reference
- https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
- Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
- Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
- Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
- Apache Hadoop YARN — Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
- Apache Hadoop YARN — Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
- Apache Spark — Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
- Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
- Apache Uniffle — Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
- Apache Uniffle — Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
- Apache Uniffle — Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
- Koordinator — CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
- Koordinator — Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/