Self-contained K8s operator for Hadoop Yarn
#Kuberbetes #hadoop #yarn #operator #systemDesign
The Kubernetes operator is a good design for custom requirements, especially for deploying infrastructure software such as databases, etc.
In fact, I'm not a cloud native engineer, I just developed the operator to deploy the Hadoop Yarn nodemanagers on the K8s. But for the 2 years experience of maintaining 2000+ Yarn nodemanagers on K8s, I want to share something about how to design a stable/effective operator that is general for any domain. In this article, I will use the yarn operator as an example to explain the underlying design reason.
First, some design rules of the operator are as follows. Details will be explained in the next section.
- Use the internal way to store pod state, which is managed in this operator to ensure self-contained.
- Keep consistent with the K8s target state design
- Ensure idempotence. the restart/recover/shutdown will happen at any time/any where.
What's the requirement
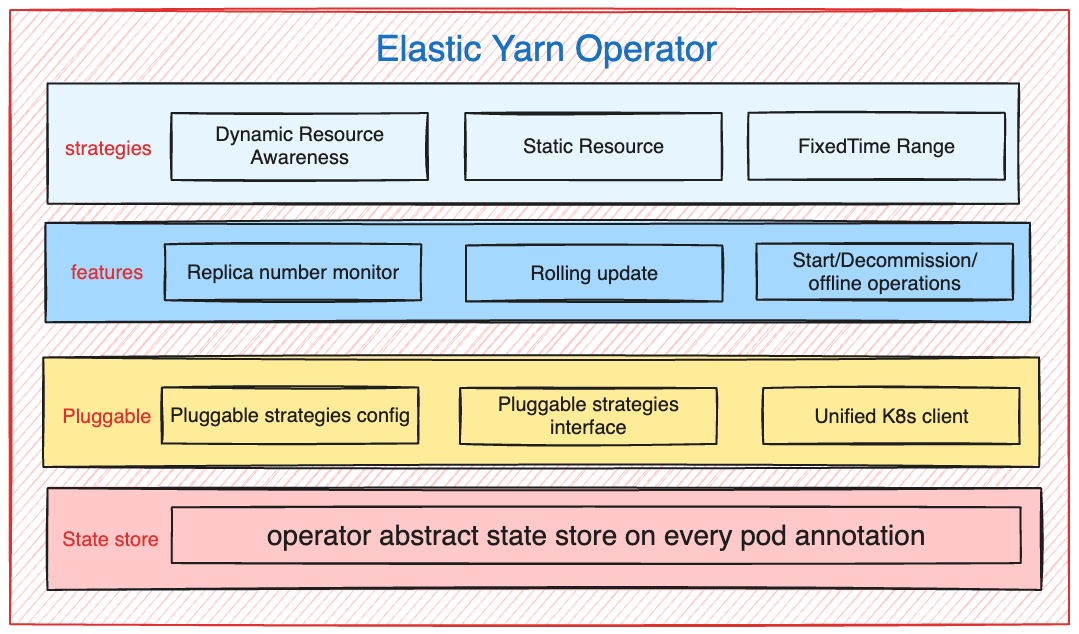
Some features we need to provide by this operator
- Manage the lifecycle of multiple Yarn NodeManager pods (0 -> 10000+), including deploy/offline/shrink/expand operations.
- Yarn NodeManager is a stateful service that should be ensured to perform the external decommissioning operation before going offline.
- Multiple management functions, not only for the replica requirements of the NodeManager, but also for the monitoring of the existing NodeManager
- Multiple deployment strategies, including DynamicResourceAwareness/FixedTimeRange. Detailed information can be found in the previous blog: iQIYI Big Data Hybrid OnPremise and Cloud Deployment.
How to do
For these requirements, let's revisit this operator design.
First of all, what's the language to implement this operator? Golang is the first choice for me, but unfortunately, this operator will have many interactive operations with Hadoop Yarn, so Java is the better choice for the bigdata area. From the Java world, the java-operator-sdk is the best solution, used by the flink-operator and other famous frameworks.
Second, to meet the requirement of multiple strategies, the pluggable mechanism must be introduced (it turned out that we introduced more strategies later). But for these strategies, I defined the unified pluggable strategy config, which must ensure forward/backward compatibility. The pluggable config like the following example
[
{
"strategy":"dynamic-resource-awareness",
"plan":[
{
"cluster-id":"xxxx",
"k8s-cluster-simple-name":"xxxxxx",
"block-wait-min-replica-number-ratio":0,
"prometheus-api-url":"xxxxx",
"nm-deployment-image":"xxxxxxxxxxx",
"nm-deployment-resource":{
"cpu":"1",
"mem":"2Gi"
},
"nm-deployment-nm-available-resource":{
"cpu":"1",
"mem":"1Gi"
},
"nm-deployment-resource-limit":{
"cpu":"150",
"mem":"600Gi"
},
"sidecar-container-resource": {
"cpu":"10",
"mem":"20Gi"
},
# "max-available-memory-GB-per-node": 250,
"no-limit-available-memory": true,
# "nm-deployment-replicas": 816,
"nm-deployment-replicas": 36,
"nm-deployment-entry-script": "/tmp/bootstrap.sh",
# "nm-deployment-entry-script": "while true; do echo hello; sleep 60;done",
"nm-deployment-spark-shuffle-version": "3.1.1",
# "max-available-cores-pre-node": 50,
# "is-decommission": true,
# "decommission-wait-timeout-min": 150,
# "is-refresh-decommission-timeout": true,
"sidecar-container-enabled": true,
"cgroup-internal-mount": true,
"sidecar-container-image": "xxxxxx",
# "is-rolling-update": true,
"cpu-over-allocation-ratio": 2.0
}
]
}
]
Lifecycle management with self-contained state store
The third is the lifecycle management of the pods, which is not easy when there are several possible states of a pod. The state of each pod should be recorded, and these separate states form the pod cluster overall state. Perhaps this is a bit abstract, so let me give you a single example for better understanding.
For example, the operator has started the 4 pods, currently each pod is running normally. Now, we want to decommission 1 pod, specified by the operator's yaml, and this pod's state will change from running to decommissioning (if the decommissioning state cannot be interrupted). And then I want to expand the pods to 5 replicas. Question: How to do this for the operator?
Obviously, the operator should start 2 extra pods to approach the target state of 5 replicas. And he should also follow the 1 departing pod to wait for it to finish and then proceed to some other operations.
For this I introduced the state machine to solve this, actually the target state approach design is available for this.
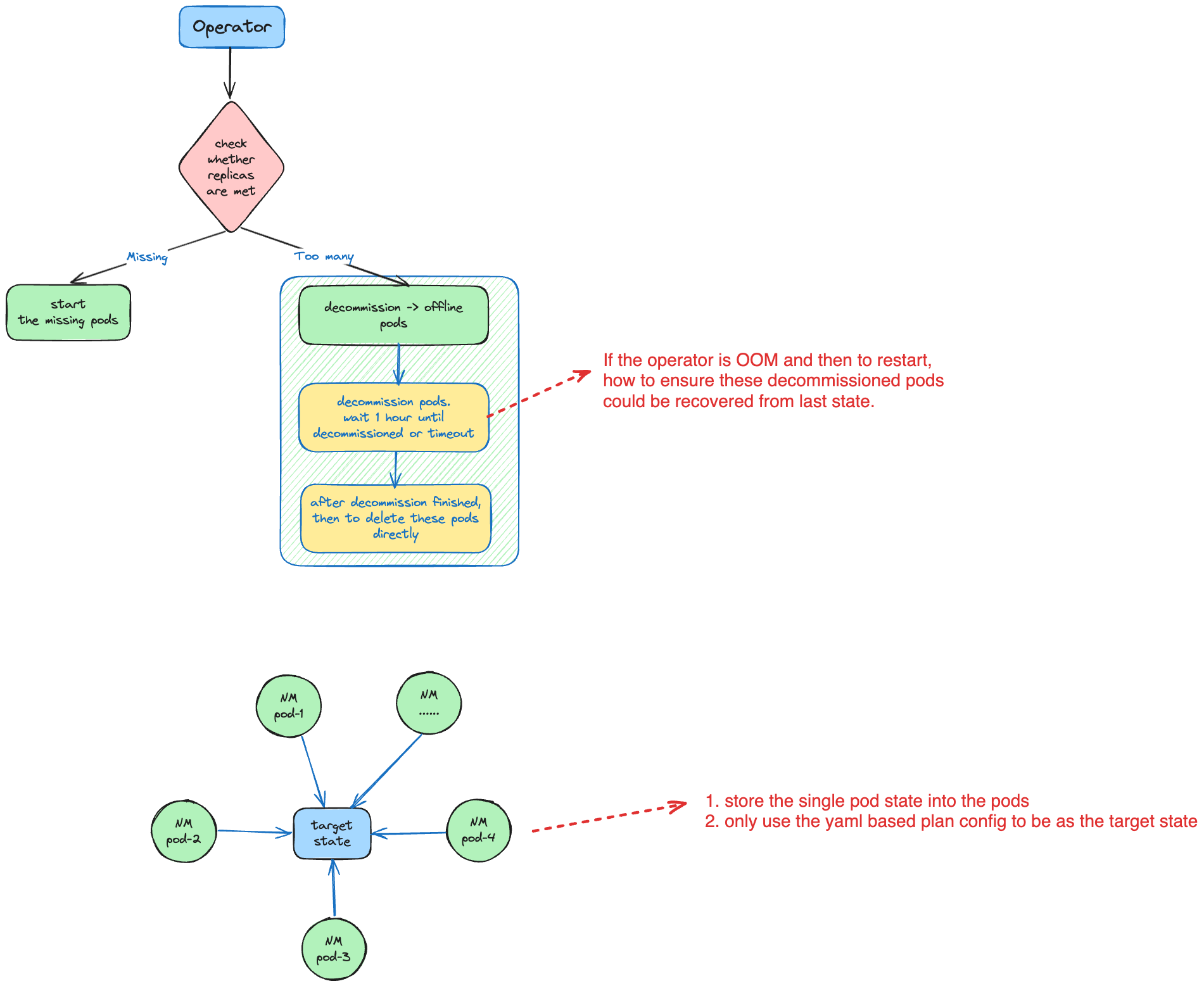
Looks simple, but we may have to deal with some corner cases. Like the operator hanging or restarting when the decommissioning is being processed. How to do this?
For these similar problems, I introduced the single pod store instead of an external remote database to do this. Every operation that changes the state is materialised in the pod annotation (I created a database abstract based on the pod annotations). So the state will be lost after operator restart.
Another critical point is that operator must make sure that before any operation happens, it will check the state whether it satisfies the target state. If not, it will approach the target state by performing some state machine operations.
This design makes the operator self-contained, the current cluster state is inferred from the separated different pods, which is retrieved from the abstract database of pod annotation contents. No external database, no local file store, everything is distributed. This is robust and stable.
Combined features implementation to share for different components
Different features should be implemented independently, but there is something that could be shared with different parts. So the combined features impl will be better than the independent style. But how to extract the shareable part? This is difficult.
I want to give an example to describe this advantage, which is rolling update.

The Rolling Update feature should control the frequency of reboots.
First, the basic general rolling update model should be introduced, which could be easily unit-tested. The push/pop related operations could be described as an abstract interface.
For this feature, the rolling update will involve 3 operations, decommissioning and then taking it offline, and then restarting with the latest image version.
Benefit from the other components, nothing will be done expecting the base rolling update model.
This is the advantage of the combined feature implementations.
Conclusion
Pluggable and self-contained design is a good thought for the modern and industry framework, not only for the K8s operator.